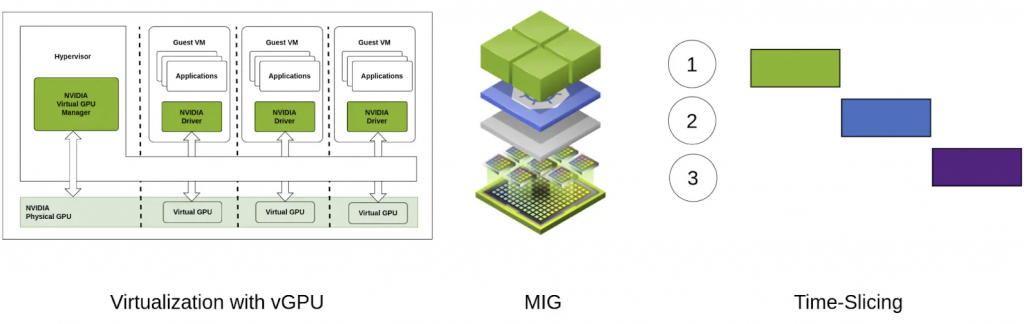
前一章節介紹了 Multi-Instance GPUs(MIG) ,屬於硬體層級的分割方法,隔離性強。那有沒有軟體切割法呢?
當然有,那就是 Time-Slicing GPUs,在 GKE 中稱為 Time-sharing GPUs。它是一種 GPU 排程和資源分配的技術,旨在讓多個使用者或應用程式能夠更公平且有效地共享單個 GPU。它與空間切片 (Space-Slicing) 形成對比,後者將 GPU 的資源(例如記憶體和計算單元)劃分給不同的使用者。
還有另一種軟體切割法 NVIDIA MPS 以下也會介紹。MPS 通過在 GPU 上創建多個上下文 (context),將 GPU 的資源分配給多個進程。每個進程擁有一個獨立的上下文(context),可以獨立執行其計算任務,仿佛擁有獨立的 GPU。 這是一種進程級別的共享。
時間切片將 GPU 的處理時間劃分為小的時間片,並將這些時間片分配給不同的使用者或應用程式。每個應用程式在分配的時間片內獨佔 GPU 資源,然後 GPU 切換到下一個應用程式。這個過程快速重複,讓每個應用程式都能獲得一定的 GPU 處理時間,從而產生一種並行執行的錯覺。
為了部署實驗環境所需的機器,可以參考 Day3 的 Terraform 範例,使用 Day3 範例創建的Cluster。新增 Node Pool 為一台 a3-highgpu-8g 的機器,配有 8 張 H100(accelerator_count=8),加上 gpu_sharing_strategy="TIME_SHARING" 參數,並使用 max_shared_clients_per_gpu 參數來設定分片數量,以下 terraform 檔案設定為 12 片。
node-pool-variables.tf
### node-pool-variables.tf
module "gke" {
node_pools = [
var.time-sharing-12.config,
]
node_pools_labels = {
"${var.time-sharing-12.config.name}" = var.time-sharing-12.kubernetes_label
}
node_pools_taints = {
"${var.time-sharing-12.config.name}" = var.time-sharing-12.taints
}
node_pools_resource_labels = {
"${var.time-sharing-12.config.name}" = var.time-sharing-12.node_pools_resource_labels
}
}
### Node pool
variable "time-sharing-12" {
default = {
config = {
name = "h100-time-sharing-12"
machine_type = "a3-highgpu-8g"
accelerator_type = "nvidia-h100-80gb"
accelerator_count = "8"
# 設定為 Time-Slicing(Sharing) GPUs
gpu_sharing_strategy = "TIME_SHARING"
max_shared_clients_per_gpu = 12
gpu_driver_version = "LATEST"
node_locations = "us-central1-c"
# 因為部署的 Pod 較多,所以將每個節點設定為可以容納 240 個 Pod
max_pods_per_node = 240
autoscaling = false
node_count = 1
local_ssd_count = 0
disk_size_gb = 2000
local_ssd_ephemeral_storage_count = 16
spot = true
disk_type = "pd-ssd"
image_type = "COS_CONTAINERD"
enable_gcfs = false
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
kubernetes_label = {
role = "h100"
}
taints = [
key = "nvidia/share"
value = "nvidia-time-sharing"
effect = "NO_SCHEDULE"
]
}
}
使用以下指令查看 Node 的標籤,可以看到會自動被打上 cloud.google.com/gke-gpu-sharing-strategy: time-sharing 的標籤,可以使用此標籤來作為 Pod 的 nodeAffinity。
$ kubectl get nodes $h100_partition_3g_Node_Name --show-labels
##...以上省略...
cloud.google.com/gke-gpu-sharing-strategy: time-sharing
我們上面設定為一台 a3-highgpu-8g 的機器,有 8 張 H100 GPU,一張切為 12 片,因此總共有 12*8=96 可以部署 96 個 nvidia.com/gpu 的 Pod。
kubectl apply -f time-slicing-deployment.yaml
# time-slicing-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: time-slicing
namespace: ai
labels:
app: time-slicing
spec:
replicas: 100
selector:
matchLabels:
app: time-slicing
template:
metadata:
labels:
app: time-slicing
spec:
containers:
- name: dcgmproftester11
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
resources:
requests:
cpu: "100m"
memory: 100Mi
nvidia.com/gpu: "1"
limits:
cpu: "1"
memory: 1Gi
nvidia.com/gpu: "1"
securityContext:
capabilities:
add: ["SYS_ADMIN"]
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.google.com/gke-gpu-sharing-strategy
operator: In
values:
- time-sharing
tolerations:
- key: "nvidia.com/gpu"
operator: Equal
value: "present"
effect: NoSchedule
- key: "nvidia/share"
operator: Equal
value: "nvidia-mig"
effect: NoSchedule
這裡將 replicas 設為 100,是為了實驗測試是不是如預測一般,只能部署 96 個 Pod,會有 4 個 Pod 無法啟動,使這些 Pod 共享 GPU 資源。
使用以下指令查詢Deployment 的 Replicas 狀態
$ kubectl get deployment time-slicing -n ai
NAME READY UP-TO-DATE AVAILABLE AGE
time-slicing 96/100 100 96 19m
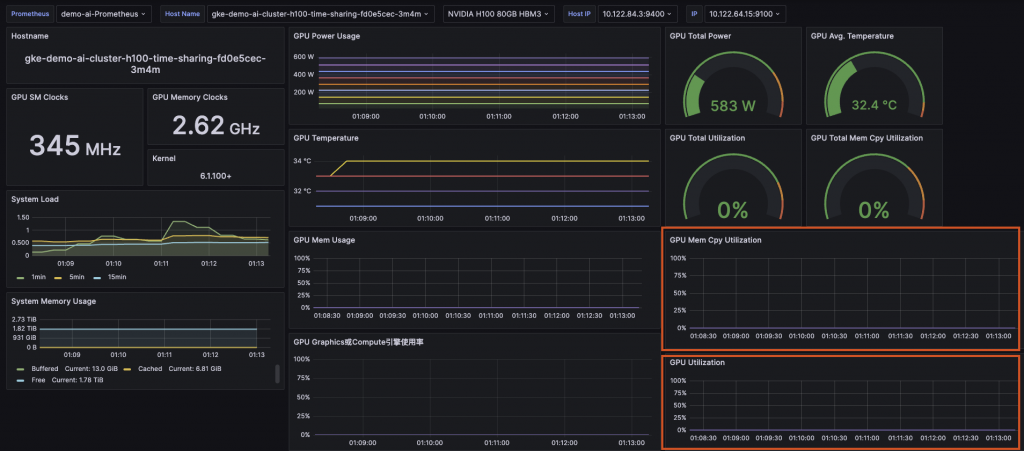
我們可以發現 GPU 在 Time-Slicing GPUs(Time-sharing) 軟體切分下,是可以監測到 GPU Utilization 及 GPU Mem Cpy Utilization,不像前一章節的的 MIG 是無法觀測到以上兩點的。
NVIDIA 多程序服務 (MPS) 是一種伺服器端架構,允許多個應用程式安全地共用單一 NVIDIA GPU,同時最大限度地提高 GPU 利用率並提供公平的資源分配。它透過提供一個控制層來實現這一點,該控制層管理 GPU 資源的分配和排程,並確保每個應用程式都能獲得執行所需的資源。
應用程式透過 MPS 伺服器連接到 GPU,而不是直接連接到 GPU 驅動程式。這允許 MPS 控制每個應用程式對 GPU 的存取。MPS 伺服器充當 GPU 資源的中央管理者。它會追蹤哪些應用程式正在執行、它們需要哪些資源,以及 GPU 上可用的資源。
為了部署實驗環境所需的機器,可以參考 Day3 的 Terraform 範例,使用 Day3 範例創建的Cluster。新增 Node Pool 為一台 g2-standard-4 配有 1 張 L4(accelerator_count=1),加上 gpu_sharing_strategy="MPS" 參數,並使用 max_shared_clients_per_gpu 參數來設定分片數量,以下 terraform 檔案設定為 6 片。
node-pool-variables.tf
### node-pool-variables.tf
module "gke" {
node_pools = [
var.l4-mps-6.config,
]
node_pools_labels = {
"${var.l4-mps-6.config.name}" = var.l4-mps-6.kubernetes_label
}
node_pools_taints = {
"${var.l4-mps-6.config.name}" = var.l4-mps-6.taints
}
node_pools_resource_labels = {
"${var.l4-mps-6.config.name}" = var.l4-mps-6.node_pools_resource_labels
}
}
### Node pool
variable "l4-mps-6" {
default = {
config = {
name = "l4-mps-6"
machine_type = "g2-standard-4"
accelerator_type = "nvidia-l4"
accelerator_count = "1"
# 設定為 Time-Slicing(Sharing) GPUs
gpu_sharing_strategy = "MPS"
max_shared_clients_per_gpu = 6
gpu_driver_version = "LATEST"
node_locations = "us-central1-a"
max_pods_per_node = 110
autoscaling = false
node_count = 1
local_ssd_count = 0
disk_size_gb = 200
spot = true
disk_type = "pd-ssd"
image_type = "COS_CONTAINERD"
enable_gcfs = false
enable_gvnic = false
logging_variant = "DEFAULT"
auto_repair = true
auto_upgrade = true
preemptible = false
}
kubernetes_label = {
role = "l4-mps-6"
}
taints = []
}
}
使用以下指令查看 Node 的標籤,可以看到會自動被打上 cloud.google.com/gke-gpu-sharing-strategy: mps 的標籤,可以使用此標籤來作為 Pod 的 nodeAffinity。
$ kubectl get nodes $l4_mps_6_Node_Name --show-labels
##...以上省略...
cloud.google.com/gke-gpu-sharing-strategy: mps
以下使用 nvidia/samples:nbody 鏡像來示範,nvidia/samples:nbody是 NVIDIA 提供的一個示例程序,用於演示 N-Body 模擬。 N-Body 模擬計算多個物體(例如恒星、行星或粒子)在相互引力作用下的運動。 這個示例程序通常用於展示 NVIDIA GPU 的計算能力,因為它可以利用 GPU 並行處理大量物體的相互作用,從而實現高速模擬。使用 CUDA 編寫,以充分利用 NVIDIA GPU 的性能。
實驗使用一台 g2-standard-4 配有 1 張切分成 6 個 MPS 的 L4 GPU,並啟動一個並行運行 10 個 Pod(容器)的 nvidia/samples:nbody 作業,經過計算每個 Pod 只能使用一個分區,所以總共只能同時啟動 6 個 Pods。
kubectl apply -f mps-test-fp64.yaml
# mps-test-fp64.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: mps-test-fp64
namespace: ai
spec:
completions: 10
parallelism: 10
backoffLimit: 1
template:
spec:
hostIPC: true
nodeSelector:
cloud.google.com/gke-gpu-sharing-strategy: mps
containers:
- name: mps-test
image: nvidia/samples:nbody
command: ["/tmp/nbody"]
args: ["-benchmark", "-i=5000","-fp64"]
resources:
requests:
cpu: "100m"
memory: 100Mi
nvidia.com/gpu: "1"
limits:
cpu: "1"
memory: 1Gi
nvidia.com/gpu: "1"
restartPolicy: "Never"
在以上 mps-test-fp64.yaml 中有幾個參數:
hostIPC: true 使 Pod 能夠與 MPS 控制守護程序通信。因此必須提供。但是,請注意 hostIPC: true 配置允許容器訪問主機資源,這會帶來安全風險。-i=5000在基準模式下運行 5,000 次叠代。-fp64 進行雙精度浮點運算nodeSelector.cloud.google.com/gke-gpu-sharing-strategy: mps 限制 Pod 在 MPS 的 Node 上運行。kubectl get pods -n ai,會發現只能同時跑 6 個 Job Pods,等有 Job 完成後才能啟動新的 Job Pod。
大約等待 6 分鐘,當有 Pod 運行完成後,使用指令查看 Pod Logskubectl logs $Pod名稱 -n ai
> Windowed mode
> Simulation data stored in video memory
> Double precision floating point simulation
> 1 Devices used for simulation
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
MapSMtoArchName for SM 8.9 is undefined. Default to use Ampere
GPU Device 0: "Ampere" with compute capability 8.9
> Compute 8.9 CUDA device: [NVIDIA L4]
Advisory: setting a high number of iterations
in benchmark mode may cause failure on Windows
Vista and Win7. On these OSes, set iterations <= 10
8192 bodies, total time for 5000 iterations: 209308.422 ms
= 1.603 billion interactions per second
= 48.093 double-precision GFLOP/s at 30 flops per interaction
在默認情況下,在 GKE 上使用 NVIDIA MPS 調度 GPU 時,系統會將以下 CUDA 環境變量注入 GPU 工作負載:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGE:此變量表示每個 MPS 共享單元可以使用的可用線程百分比。默認情況下,GPU 的每個 MPS 共享單元都設置為 100 / MaxSharedClientsPerGPU,從而根據流多處理器獲得相等的 GPU 計算切片。CUDA_MPS_PINNED_DEVICE_MEM_LIMIT:此變量用於限制 GPU 的 MPS 共享單元可以分配的 GPU 內存量。默認情況下,GPU 的每個 MPS 共享單元會設置為 total mem / MaxSharedClientsPerGPU,以獲取相等的 GPU 內存切片。使用以下指令進入部署在 mps GPU 的 Pod,可以看到被切分成 6 份 MPS 單個 Pod 的資源使用量。
$ exec kubectl exec -i -t -n ai $Pod_Name -c mps-test -- sh -c "clear; (bash || ash || sh)"
root@Pod_Name$ echo $CUDA_MPS_ACTIVE_THREAD_PERCENTAGE
16
root@Pod_Name$ echo $CUDA_MPS_PINNED_DEVICE_MEM_LIMIT
0=3839M
將 resources.requests.nvidia.com/gpu 及 resources.limit.nvidia.com/gpu 改成 2,會發現同時只能有 3 個 Pod 同時運行,再進入 Pod 使用指令查詢環境變數。
resources:
requests:
nvidia.com/gpu: "2"
limits:
nvidia.com/gpu: "2"
$ exec kubectl exec -i -t -n ai $Pod_Name -c mps-test -- sh -c "clear; (bash || ash || sh)"
root@Pod_Name$ echo $CUDA_MPS_ACTIVE_THREAD_PERCENTAGE
33
root@Pod_Name$ echo $CUDA_MPS_PINNED_DEVICE_MEM_LIMIT
0=7678M
從以上變數可以看到,可以使用 GPU 33% 的活動線程資源,鎖定的內存大小為 7678MB,可以使用的資源量是設定 resources.requests.nvidia.com/gpu=1 的 2 倍。
同時使用以下指令進入部署在 mps GPU 的 Pod,可以看到單個 Pod 使用 2 個 MPS GPU 的資源使用量,取得的算力大約是resources.requests.nvidia.com/gpu=1 的 2 倍。
18432 bodies, total time for 5000 iterations: 470835.406 ms
= 3.608 billion interactions per second
= 108.235 double-precision GFLOP/s at 30 flops per interaction
本文介紹了兩種 GPU 軟體切分方法:Time-Slicing 和 NVIDIA MPS。Time-Slicing 將 GPU 時間片分配給不同應用,並可監控 GPU 利用率。MPS 則透過建立多個上下文,讓多個進程共享 GPU 資源,提高利用率並公平分配。
文章以 Terraform 部署 H100 及 L4 GPU Node Pool 為例,示範如何設定 Time-Slicing 和 MPS,並使用 Deployment 和 Job 進行測試。實驗結果顯示 Time-Slicing 部署受限於切片數量,而 MPS 則限制了 Job 的並行數量。 值得注意的是,MPS 需要 hostIPC: true 才能與控制守護程序通信,但這會帶來安全風險。
雖然兩種方法都能提升 GPU 使用效率,但仍需考量各自的限制和安全性,選擇適合的方案。

